

Due to the rapid growth of digital procedures, the possibilities of fraudulent activities have been on the rise, especially in the insurance and financial sector. Fraudulent activities, such as false claims or transactions, are costing corporations millions of dollars every year, which leads to annual financial losses. It is challenging for conventional cybersecurity methods to implement potential preventative detection techniques to identify these fraudulent claims. Not to mention, 24/7 human surveillance is no longer enough to continuously track increasing volumes of data attacks. So, it is challenging for today’s insurance and finance companies to keep up with the modern cyber threats.
Thanks to Artificial Intelligence (AI) technology, AI is a one-stop solution for banking, financial services, and insurance companies to block intruders. It prevents frauds from accessing user accounts or reducing the occurrence of fraudulent claims. In this article, you learn how V-Soft Consulting helped the client identify fraudulent claims through developing an AI-driven fraud detection application.
Pain Points That the Client Had Experienced
One of our clients was facing difficulties in identifying potential fraudulent claims made by fraudsters. These false claims cost the client millions of dollars, which resulted in financial losses every year. The client also made significant investments in the manual workforce to verify and detect a high volume of fake insurance claims, which resulted in process delays and operational inefficiencies. Moreover, the client’s current rule-based systems have high false positive and false negative rates, making them ineffective.
To reduce the occurrence of fraudulent claims and prevent financial losses, the client partnered with V-Soft Consulting to develop an intelligent AI and Machine Learning (ML)-powered automation solution that can speed up the claim’s verification processes while lowering costs.
V-Soft Addressed Challenges with Generative AI Fraud Detection Model
To combat the intruder attempts, one must think like a hacker. This approach will help companies identify possible vulnerabilities and deploy advanced solutions to protect their information systems and entire network infrastructure. At V-Soft, we have applied the same strategy to help our client identify fraudulent claims with AI-enabled fraud detection software solutions that use ML models and Generative AI for process efficiencies. Let’s take a look at the step-by-step process involved in the procedure.
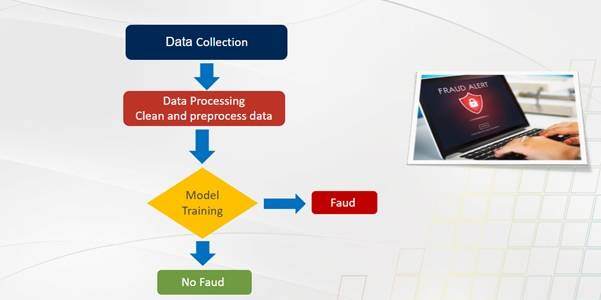
Step-1: Data Collection for Pre-Processing
Collecting data is the core asset for executing any AI-based fraud detection system. This phase collects information from historical claims, demographics of policyholders, claim amounts, and known fraud labels. In this phase, unstructured data will be collected from the relevant sources and formatted to process.
- Claims Data: Any data regarding previous claims filed, including the claim amount, transaction dates, claim processed date, and insurance policy or claim type.
- Customer Data: The data about the policyholders’ demographic information, such as age, gender, location, and occupation.
- Transaction Data: All payment-related data, such as the date of premium payments as well as the fake transactions, if any, will be considered.
- External Data: It involves public data records, activity on social media, and third-party databases to add another dimension to the model.
Step-2: Data Cleaning and Transformation
Primary data or raw data is an asset for the model, but it requires extensive clean-up to work with. Here data cleaning and data transformation will come into the picture.
Data cleaning and data transformation are two distinct procedures that work together to remove invalid data from raw data and convert it into a useful format for an efficient data analysis. The functionalities of both processes complement each other. This data cleaning tool fixes errors in your data, removes duplicates, and normalizes data into a single format. On the other side, data transformation techniques create new features from existing data and replace missing values by validating data collected from several sources.
V-Soft’s experts have conducted rigorous data cleaning, handled missing values, performed feature engineering, and normalized the data to ensure that the dataset is accurate and complete. Here are the key steps involved in this phase.
- Handling Missing Data
In this phase, the model identifies missing values either by mean substitution or the more robust procedure known as K-Nearest Neighbors (KNN) imputation techniques.
- Data Normalization
Using min-max scaling or Z-score normalization techniques, the features that are measured on different scales should be normalized so that the model is handling all features equally.
- Feature Engineering
Feature engineering is one of the crucial steps in AI-fraud detection models to derive new features from existing variables (raw data) and enhance models’ performance. It cleans up claims data, helping ML models to efficiently use it for detecting fraud.
Step-3: AI Models for Insurance Fraud Detection
Implementing the robust tree-based machine learning algorithms, such as Random Forests, Gradient Boosting Machines, and deep learning models, such as neural networks, V-Soft helped the client to analyze vast volumes of claims data and forecast the volume of fraudulent insurance filings in real-time.
Later, we also used Generative Adversarial Networks (GANs) to create synthetic datasets that simulate fraud behavior. This strategy will enhance the accuracy of the training dataset and empower the solution to recognize fake claims faster. The following models were trained and tested using historical data and validated using cross-validation techniques.
- Logistic Regression
The base model used for binary classification, such as fraud detection. The logistic regression model gives the probability that a particular instance belongs to the class of fraud.
- Decision Trees and Random Forests
Decision trees segregate the dataset into branches based on feature values, leading to a decision about whether a claim is fraudulent or legitimate.
- Support Vector Machine
Support Vector Machine (SVM) is a highly efficient algorithm for processing high-dimensional data. It can process feature-based complex relationships by finding the right hyperplane that separates fraud cases from the non-fraud ones.
- Neural Networks and Deep Learning
Neural Networks come into use for higher dimensional data such as images or videos when dealing with bigger datasets like auto insurance claims.
Step 4: Model Training and Cross Validation
Training the AI-powered fraud detection model with the preprocessed data plays a key role in the entire automation procedure. Here, the model will learn the relationships between the features that targeted variables that have been selected in the previous phase.
Later, to increase the generalizability of the model, cross-validation techniques like k-fold cross-validation have been used. Here, the complex dataset is segregated into k subsets so that k-1 subsets are used for training the model and the other subsets are validated. Then this whole process must be repeated k times so that the average of all those performances turns out to be more robust for the assessment of the model's performance.
Step 5: Key Evaluation Metrics
Because the data is imbalanced, it is important to evaluate a fraud detection model efficiently in order to deliver the precise outputs. The metrics are:
-
Accuracy: The fraction of correctly identified fraud cases among all cases labeled as fraud.
-
Recall: The rate of true fraud cases that were captured precisely.
-
F1 Score: Harmonic Mean score of the precision and recall score, in which the input has been balanced.
-
ROC-AUC: The area under the Receiver Operating Characteristic curve, which plots the true positive rate against the false positive rate, providing a single metric reflecting the ability of the model to distinguish between classes.
Step 6: Deployment, Monitoring, and Upgrading
It manages the monitoring of the model's performance from the day it's deployed. This analysis will be helpful for feature enhancements and upgrading the model for more accurate results.
Conclusion
Since the insurance industry continues to struggle with growing fraudulent attempts, deploying AI-powered fraud detection models that are built with Generative AI capabilities is the best strategy. From automating claims underwriting to predicting fraudulent attempts, the benefits of Generative AI in insurance fraud detection are incredible.
Our scalable Gen AI-powered fraud detection app automated the process and resulted in a 60% reduction in claim processing time and a 50% reduction in manual efforts. Thus, it is allowing their staff to focus more on complex claims, thereby boosting productivity.
