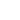


Named Entity Recognition (NER) is an application of Natural Language Processing (NLP) that processes and understands large amounts of unstructured human language. Also known as entity identification, entity chunking and entity extraction. NER extraction is the first step in answering questions, retrieving information and topic modeling. There are many models for implementing NER depending on the application need. Here we compare Spacy pre-trained and Stanford NER models.
Applications and Use Cases of NER
NER has various applications in multiple industries such as news and media, search engines, and content recommendations.
Use Cases of Named Entity Recognition:
- Information Extraction Systems
- Question-Answer Systems
- Machine Translation Systems
- Automatic Summarizing Systems
- Semantic Annotation
Approaches for NER Workflow for NER
Workflow for NER
An NER System is capable of discovering entity elements from raw data and determines the category the element belongs to. The system reads the sentence and highlights the important entity elements in the text. NER might be given separate sensitive entities depending on the project. This means that NER systems designed for one project may not be reused for another task.
For a general entity such as name, location, organization, date and pre-trained library, Stanford NER and Spacy can be used. But for a domain specific entity, an NER model can be trained with custom training data requires lots of human efforts and time. There are a few other approaches such as, Feedforward Neural Networks for NER, BILSTM, CNNS, and Residual Stack BILSTMS with Biased Decoding which can be used to perform NER using deep learning.
Spacy Pre-trained vs Stanford NER Model
Stanford NER
This is implemented in Java and is based on linear chain CRF (Conditional Random Field) sequence models. For various applications, custom models can be trained with labeled data sets.
It has three models:
- 3 class : Location, person, organization
- 4 class : Location, person, organization, misc.
- 7 class : Location, person, organization, money, percent, date, time
Model Architecture
Stanford NER stated that Conditional Random Field (CRF) is a sequence modeling algorithm that assumes features are dependent on each other, and also considers future observations while learning a new pattern. This combines the best of HMM (Hidden Markov Model) and MEMM (Maximum Entropy Markov Model). In terms of performance, it is one the best methods for entity recognition problems.
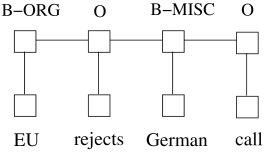 Figure: Conditional Random Field Model
Figure: Conditional Random Field Model
Installation steps
- Since it is written in Java, Java JRE must be installed and set to the environment path.
- Download the zip file stanford-ner-xxxx-xx-xx.zip from the Stanford NLP website. Unzip it and place it in the application folder.
- Install the NLTK package using command: pip install nltk
Example: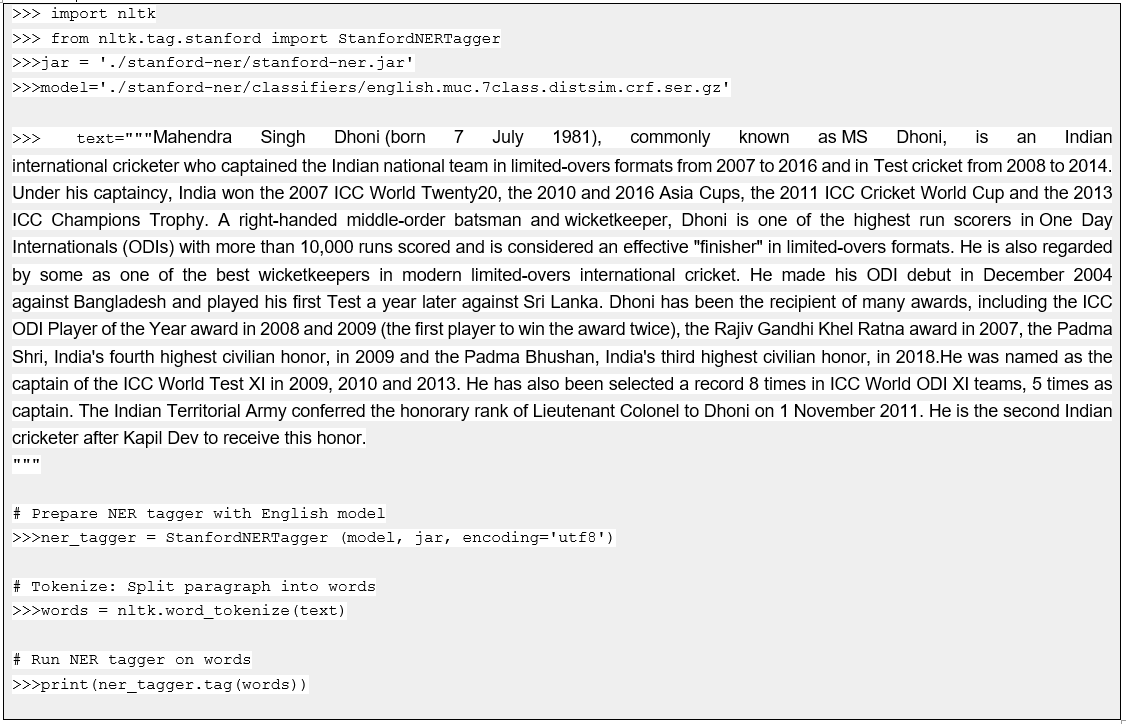
Result
Spacy NER
Spacy is an open source library for natural language processing written in Python and Cython, and it is compatible with 64-bit CPython 2.7 / 3.5+ and runs on Unix/Linux, macOS/OS X and Windows. Spacy provides a Tokenizer, a POS-tagger and a Named Entity Recognizer and uses word embedding strategy. The advantage of Spacy is having Pre-trained models in several languages: English, German, French, Spanish, Portuguese, Italian, Dutch, and Greek.
Model Architecture
The current architecture of a Spacy model hasn’t been published yet, but the above video explains how the models work, with particular focus on NER.
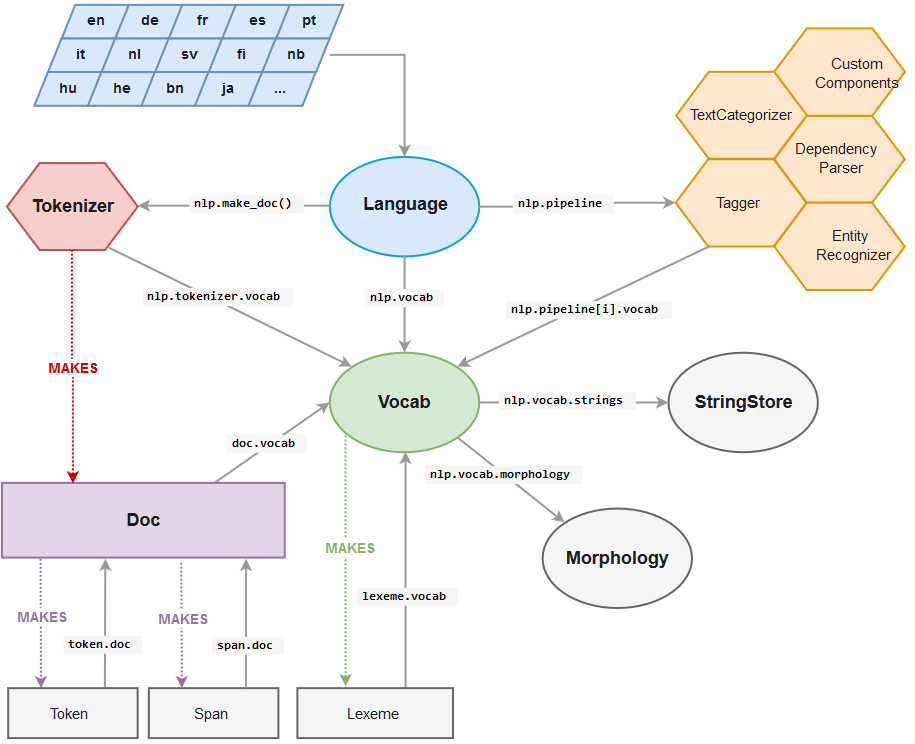 Figure: Spacy Library Architecture
Figure: Spacy Library Architecture
The Spacy NER system contains a word embedding strategy using sub word features and "Bloom" embed, and a deep convolution neural network with residual connections. The system is designed to give a good balance of efficiency, accuracy and adaptability.

Figure: Spacy NER Architecture. Language processing pipeline
Installation Steps
- pip install -U spacy
- Once installation is complete, pre-trained models for specific languages can be installed and used in the application.
- Python -m Spacy download en
Example:
Output:
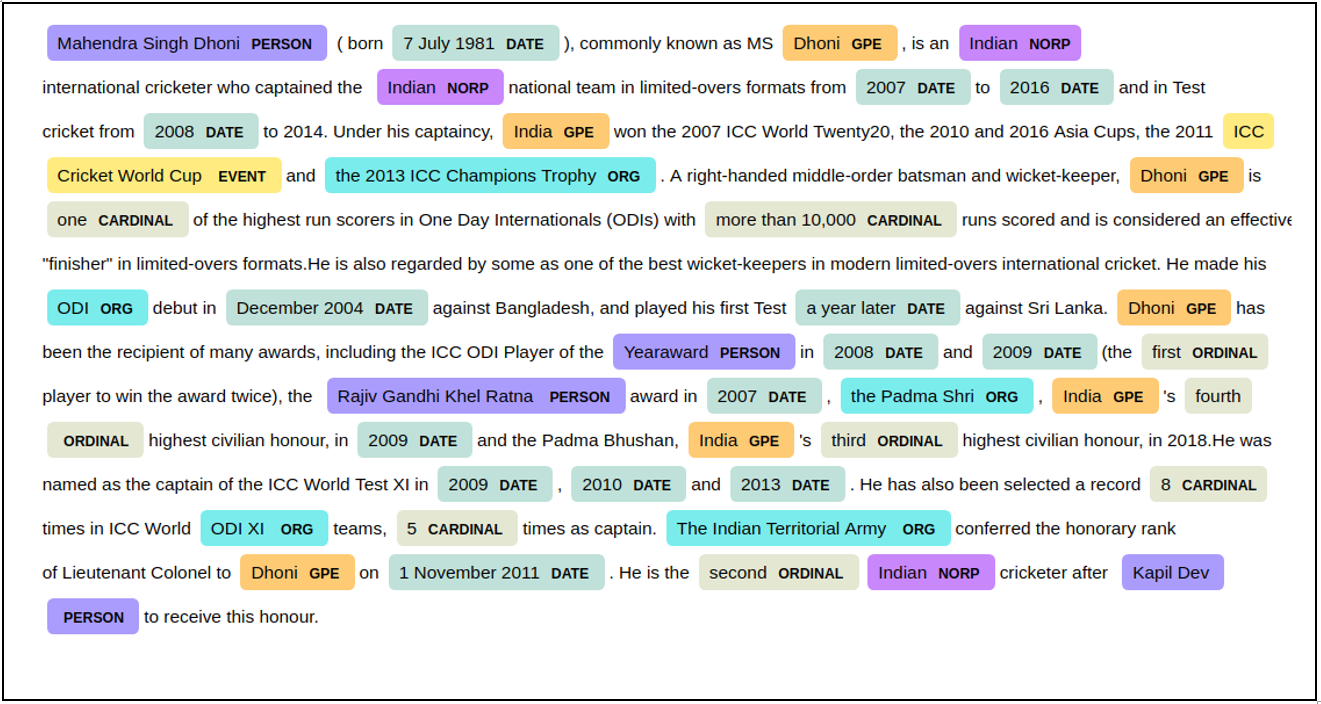
Conclusion
Comparing results from Spacy as well as NLTK implementation of Stanford NLP concludes that both can be used for NER to achieve good results. Spacy has support for word vectors, so it's fast and accurate. It is recommended to use Spacy NER for production over Stanford NER. For customizing the process of NER, both models can be used. This requires data labeling and annotation which means giving NER tags to entities.

About Author
 Durga Bhavani works as a Data Scientist with V-Soft Digital. As a Data She has 3 years of experience as a Data Scientist and has extensive knowledge on predictive modelling, data processing, and data mining algorithms. In her professional experience, she has developed applications in Deep Learning, Python, Machine Learning, and Natural Language Processing (NLP). She holds certifications in Natural Language Processing and Computer Vision. Out of her strong interest in higher mathematical concepts relating to AI, currently she is also pursuing Post Graduation program in Mathematics.
Durga Bhavani works as a Data Scientist with V-Soft Digital. As a Data She has 3 years of experience as a Data Scientist and has extensive knowledge on predictive modelling, data processing, and data mining algorithms. In her professional experience, she has developed applications in Deep Learning, Python, Machine Learning, and Natural Language Processing (NLP). She holds certifications in Natural Language Processing and Computer Vision. Out of her strong interest in higher mathematical concepts relating to AI, currently she is also pursuing Post Graduation program in Mathematics.
