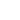


Most neural networks can be easily fooled by adding small amounts of noise to actual data. Even such a small amount of noise has a huge impact and affects the end result with wrong predictions. In this blog, we discuss how Generating Adversarial Networks (GANs) are used in improving document enhancement.
Working of GANs
GANs are unsupervised learning models that are composed of generator and discriminator models. The generator generates fake data almost identical to actual data to try and fool the discriminator. The discriminator's job is to distinguish between actual data and fake data generated by the generator. The generator and discriminator are both neural networks trained in parallel. So that in parallel, the generator gets trained to generate fake data and the discriminator is trained to identify fake data from actual data (refer to the below figure).
Let’s understand this using a popular example of the forger (generator), whose task is to create fraudulent imitations of original paintings by famous artists. If he can pass off this work as an original art piece, the forger can potentially get a lot of money out of it. On the other hand, there is an investigator (discriminator) whose task is to catch these forgers. Here the investigator is fully aware of the properties of original paintings and able to differentiate between the original and the forged one. This contest of forger and investigator goes on, which ultimately makes best investigator and forger.
The competition between these two models is what improves their knowledge until the generator succeeds in creating realistic data. Discriminator weights are updated to maximize the probability that any real data input is classified as belonging to the real data set while minimizing the probability that any fake data is classified as belonging to real data sets.
Here are the few applications of GANs:
- Semantic image to photo translation.
- Super-resolution
- 3D object generation
- Clothing translation
- Photograph editing
- Image enhancement
Conditional Generative Adversarial Networks (CGANs)
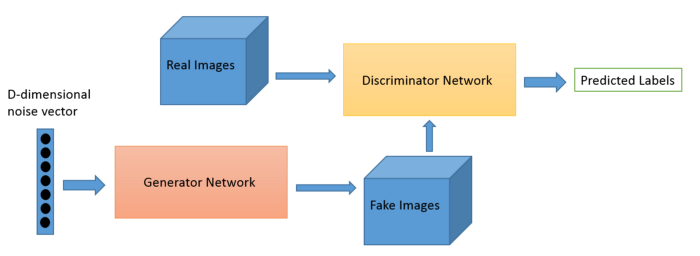
In GAN, there is no control over models of the data to be generated. The conditional GAN changes that by adding the "label y" as an additional parameter to the generator and hopes that the corresponding images are generated. We also add the labels to the discriminator input to distinguish real images better.
 Figure: Architecture of Conditional Generative Adversarial Networks
Figure: Architecture of Conditional Generative Adversarial Networks
Generative adversarial nets can be extended to a conditional model if both the generator and discriminator are conditioned on some extra information y. The y could be any kind of auxiliary information, such as class labels or data from other modalities. We can perform the conditioning by feeding y into both discriminator and generator as an additional input layer.
The generative model is trained to generate new samples from the input domain along with some additional input. The discriminator is also conditioned by adding some additional information along with input images which can be either real or fake. For example, if we would like to convert horse type to zebra type images, then one generator side must be a condition y, and input to the generator must be a horse but not anything else.
Cycle Generative Adversarial Networks (CGans)
Image to image translation is a goal to map input and output image pairs using a trained set of aligned image pairs. But getting the aligned image pairs for training is a complex task. Thus CycleGans (CGans) are helpful in translating an image from domain X to domain Y without paired images.
For CGans, there will be two generators, G and F. Generator G has a goal to map from domain X to domain Y (G: X->Y), and the other Generator F has a goal to map from domain Y to domain X (D:Y->X). Both these generators have their respective discriminators, Dy and Dx, while these Dx and Dy are models are designed to distinguish between input and output images.
CycleGans are used to convert one source of the domain to another source and vice versa where there is a lack of data. The below image is a sample output of a model which is trained using CycleGan, where zebra images are converted to horse images and similarly horse images are converted to zebra images.
CycleGANs Implementation Document Cleaning
CycleGans can clean documents via denoising or by background noise removal, deblurring, watermark removal and defading for improving readability. Sample datasets can be obtained from kaggle document dataset and BMVC deblurring document datasets.
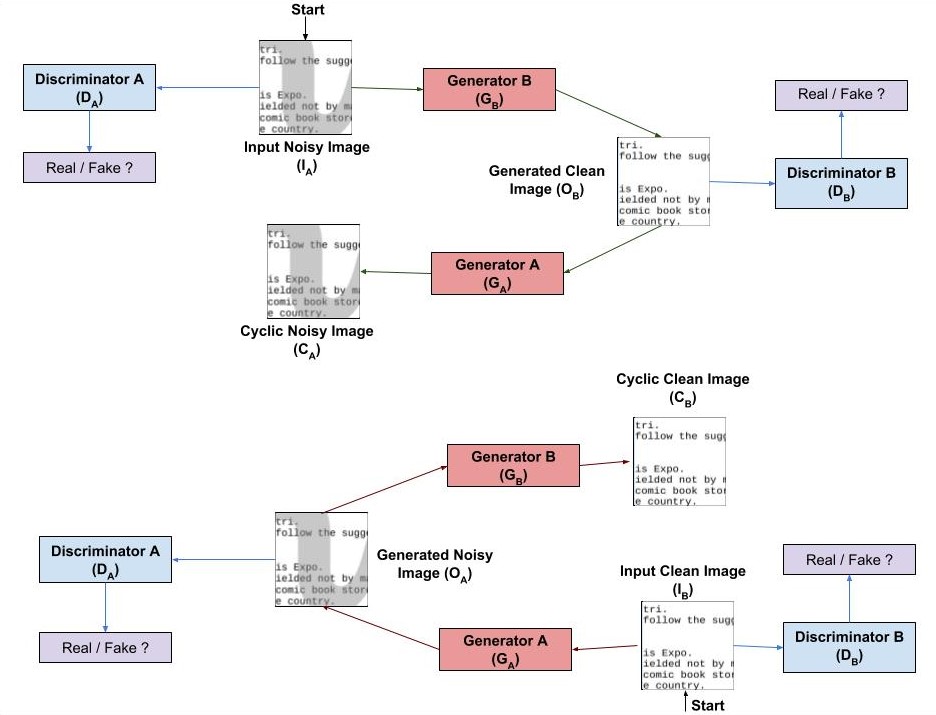
Figure: CycleGANs Implementation of Document Cleaning Process
As shown in the above figure, the first generator GB maps the image from noisy domain A (IA) to output image in target clean domain B (OB). To make sure that a meaningful relationship exists between IA and OB, they must learn some features which can be used to map back OB to the original noisy input domain. This reverse transformation is carried by the second generator GA which takes input OB and converts it back into an image CA in the noisy domain.
A similar process of transformation is carried out for converting images in clean domain B to noise domain. Here both discriminators will take two inputs, original image, and images generated by the generator. Discriminators task is to reject the fake images i.e., images generated by the generator. Thus generator tries to provide more accurate images in a way it is similar to the original image.
The generator network consists of two Conv2D layers of stride 2, several skip connections (residual blocks) and two layers of transposed conv2D with stride 1. The discriminator network uses 70 X 70 PatchGans to classify 70 X 70 overlapping patches of images as real or fake.
Experimental Results
Below are some sample results after removing noise from the documents.

Conclusion
It is difficult to obtain clean images corresponding to a noisy image. CycleGANs are preferred because it works well for unpaired data sets. CycleGANs are not only for image data sets but also for the image to text, speech to text and text to text conversions.

 About Author
About Author
Ravi Teja works as a data scientist at V-Soft Digital. He holds a masters degree from the University of Hyderabad in Artificial Intelligence specialization. He is very much passionate about developing applications related to computer vision, Natural language processing with Keras and TensorFlow backend. He has hands-on experience in Opencv(python), Matlab and Tableau (data visualization).
