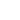


We use Google almost every day, be it in our work or personal lives. Have you ever wondered how the Google search process provides such accurate information from such a vast amount of data? Google, like most search engines, uses a sophisticated knowledge graph on the backend. Many of these advanced concepts are powered by knowledge graphs using artificial intelligence.
What is a Knowledge Graph?
Knowledge graphs are used to search, store and present fact-based data and are also used to power search engines, recommendations and chatbots. Knowledge graphs contain a head entity, relation and a tail entity, or in simpler terms: subject, relation and object.
Building a Knowledge Graph for Search Engines
This process has three steps:- Generate triples from relevant text
- Store triples in graph database
- Query the knowledge graph
Step 1: Generating Triples from Relevant Text
Part 1: Extract Entity
Named entity extraction is a popular technique used in information extraction, which takes the entities from the text based on predefined classes. Different Named Entity Recognition (NER) systems generate entities from the given text.
- Spacy NER, Stanford NER
- Pretrained models like BERT, Elmo
- Machine learning algorithms like conditional random fields
- Deep learning algorithms like Bidirectional LSTM-CRF, LSTM-CNN
Part 2: Identify Relationship Between Entities
Once the entities are extracted from the text, we must find the relation between these entities, such as extracting semantic relations between two or more entities. For example, "The White House is in Washington D.C." Here, "The White House" is the head entity in the relation and "Washington D.C." is the tail entity. This can be represented as a triple (The White House, is in, Washington D.C.)
There are different methods for doing Relation Extraction (RE):
- Rule-based RE
- Supervised RE
- Unsupervised RE
Alternatively, we can use the below-mentioned tools to extract triples from documents.
- Open source Python module Stanford-OpenIE
- IBM Watson NLU service
How to Generate Triples Using the Stanford-OpenIE Python Module
- Since it is written in Java, make sure Java 1.8 is installed in your system
- If OS is a Windows system, download and install the Java and set the path
- Install Stanford-OpenIE Python package using below command:
- pip install stanford-openie
The OpenIE is supporting only 100,000 characters, so the length of the text must be below 100,000 characters. To execute, run the below code by passing input text and file name of csv to store triples:
Step 2: Storing Triples in Graph Database
Graph databases are designed to store nodes and their relations (edges). Graph databases give priority to relationships. Unlike other database management systems, in graph databases, connected data is equally important to individual data.
Applications of Graph Databases:
- Knowledge Graph
- Recommendation Engine
- Fraud Detection
Available Graph Databases:
- ArangoDB
- Neo4j
- OrientDB
- Amazon Neptune
- FlockDB
- DataStax
- Cassandra
- Cayley
Here's how to store generated triples in Neo4j. Neo4j is available in two editions.
- Community edition: Designed for single-instance deployments
- Enterprise edition: Included all the features of community edition and has extra features like clustering and online backup
Installation steps for community edition:
- In windows, download neo4j and install it
- In ubuntu, Java has to be installed to install neo4j. Follow the steps in the below link to install neo4j in ubuntu
Once the installation is completed, neo4j can be accessible in the browser. The default username and password for the browser version is neo4j. Install py2neo package using the below command: pip install py2neo
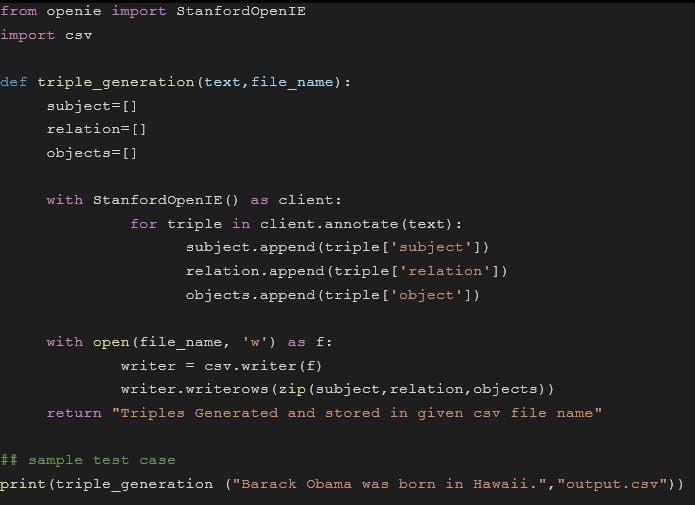
Now give the output.csv (which is generated from the previous step) as input to the above code to store triples in neo4j database. You should now be able to visualize a knowledge graph in neo4j database.
Step 3: Querying the Knowledge Graph
You can start searching nodes in the neo4j web browser.
Sample query:
MATCH (n: Subject) RETURN n LIMIT 25
- This query matches the nodes with label Subject and returns 25 results
- You can select the label from Subject and Object and query the graph or you can access the neo4j graph with credentials using Python script

About Author
 Durga Bhavani works as a Data Scientist with V-Soft Digital. She has 4 years of experience as a Data Scientist and has extensive knowledge on predictive modelling, data processing, and data mining algorithms. She has developed applications in Deep Learning, Python, Machine Learning, and Natural Language Processing (NLP). She holds certifications in Natural Language Processing and Computer Vision. Out of her interest in higher mathematical concepts relating to AI, currently she is also pursuing Post Graduation program in Mathematics.
Durga Bhavani works as a Data Scientist with V-Soft Digital. She has 4 years of experience as a Data Scientist and has extensive knowledge on predictive modelling, data processing, and data mining algorithms. She has developed applications in Deep Learning, Python, Machine Learning, and Natural Language Processing (NLP). She holds certifications in Natural Language Processing and Computer Vision. Out of her interest in higher mathematical concepts relating to AI, currently she is also pursuing Post Graduation program in Mathematics.
