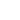


The overall development and growing era of the 21st century is reflected in different fields and use-cases. Computer vision has shifted its pace from old statistical methods to deep learning neural network methods. It is widely used in place for facial recognition with indexing, photo stabilization or machine vision. Major applications have been developed to process the image data and generate insights from it. Here we discuss the evolution of various deep learning architectures that deal with processing image data.
Classification of Images
The journey of deep learning originates with the classification problem of image data sets. Images with objects like cats or dogs must be classified into a given set of categories or labels. For this task, Convolutional Neural Network (CNN) must be trained with images and its corresponding labels.
Understanding Convolutional Neural Network
CNN works with the principle of convolution, which is a form of matrix multiplication which will down-sample the features to a matrix/vector of features. The resultant matrix or vector is later given to a layer of neurons which will further transform the vector to a single value vector. This single value will be later identified as the label. 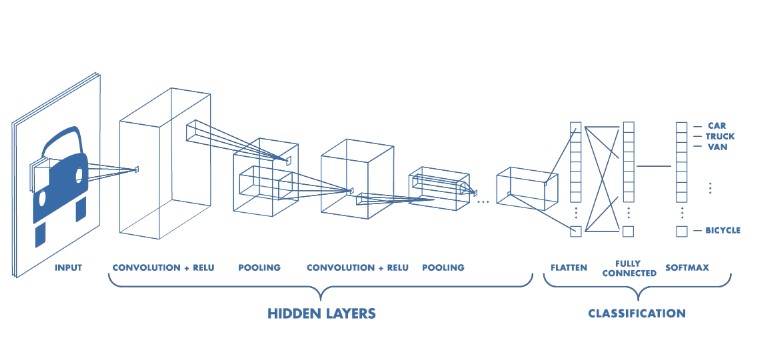
Figure: Architecture of a CNN. Source: Mathworks
The architecture of basic fully connected CNN includes an input layer to take an image as input, convolution layers, max-pooling layers and dense layers in the hidden layer followed by an output layer which includes flattening layers, a fully connected layer and a activation layer which will determine the label for the image.
Detection & Recognition
Classification of images is a straightforward task. The image contains only one object and the entire image is entitled to that object which is presented as label. The next problem raised in this field is the task of recognizing the particulars of this object. For example, face recognition, dog breed recognition, license plate recognition & extraction of the license number. The idea behind this task is to identify the object and identify the features of this object to further classify or recognize the features. A famous architecture for this problem is Inception Net. It is designed to identify objects of various sizes in the image- called a Multi-Label, Multi-Class classification. Inception Net is trained to identify the different sizes of multiple objects in the images.
Using the model for Inception Net, we can also solve the problem of recognition in the image. Since Inception Net provides multi-resolution object recognition, labels related to human faces can also be identified from the image. Architecture of Inception Net includes multiple bunches of CNN layers whose output is linked together to generate the output label for the image.
Object Detection (Single & Multiple)
Image classification and image recognition have seen many advances and deep neural architectures which give better accuracy than the previous one. Some of the well-known architectures include Alex Net and VGG. Both these architectures involve multiple convolution as well as pooling layers that increase computing requirements but solve complex problems.
We have discussed binary classification, which means classifying the image into two classes, multi-class classification which means classifying the image into multiple classes and multi-label classification & recognition which means identifying the objects with varying resolution. The next problem in the computer vision field is to solve the multi-label multi-class classification problem. Multiple objects with their location coordinates in a single image need to be identified. The location coordinates are considered regional features of the object.

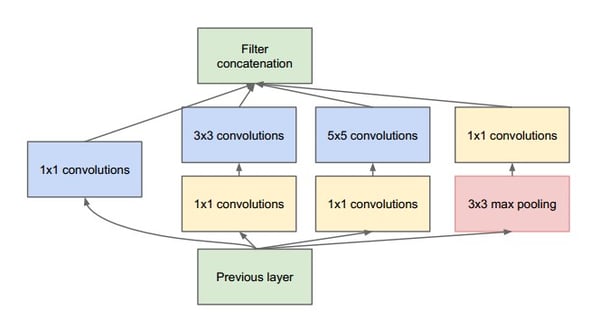
Figure: Real time multi-label and multi-class detection
YOLO model is designed to solve this problem. YOLO Model which stands for ‘You Only Look Once’, include reduction of computation required when compared to other architectures for detecting multi-label objects in the same image. YOLO model outputs 5 parameters, x, and y (geometric coordinates), w and h (dimensions of the object) and probability percentage.
 Figure: YOLO object detection with OpenCV
Figure: YOLO object detection with OpenCV
The architecture of YOLO model has a convolution model with multiple filter sizes, all constructed to one fully connected layer at the end for collecting the results of the hidden layers. The activate layer is designed to get the results from the model. The architecture is presented in the following image.
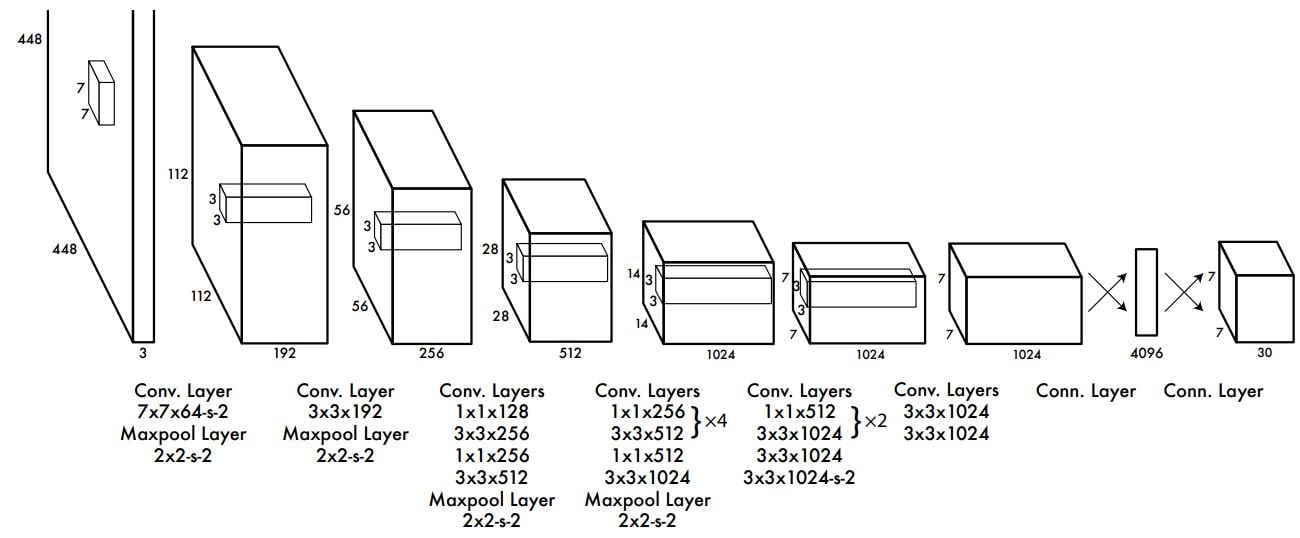
Semantic Segmentation
Now that regional object detection is achieved it became essential to detect the object without failing to detect the objects present under the bounding box of another object. A concept in image processing which presents the idea of pixel level segmentation is called Semantic Segmentation of images.
The objective of semantic segmentation is to identify the object in the image at the pixel level. This task is called dense prediction as we are processing every pixel of the image. 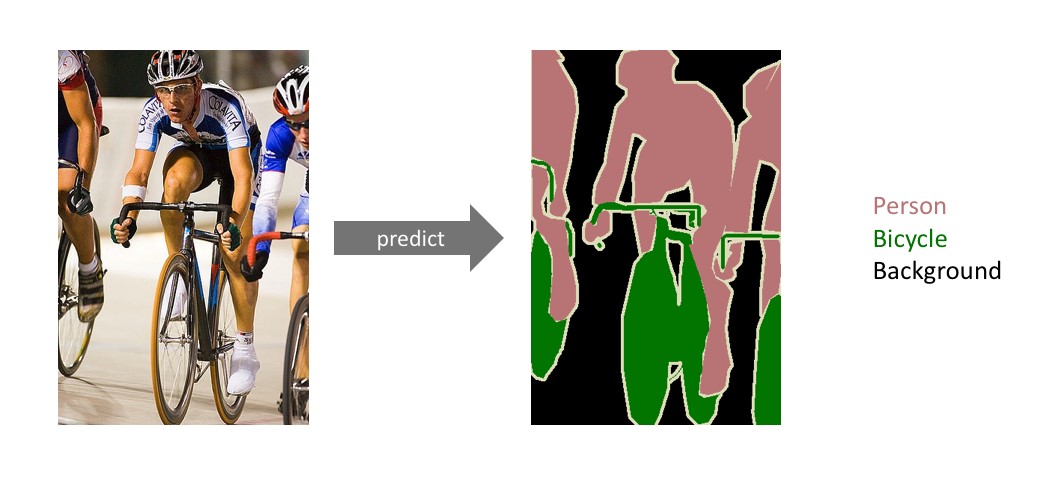
The application of semantic segmentation is included in various domains which deal with computer vision, for example, autonomous vehicles, medical image diagnosis. The architecture of CNN's is designed to down-sample the image or reduce the image resolution and identify the features of a single object. For Semantic Segmentation, we use down-sampling along with up-sampling, which restores the image resolution and identifies all the objects with pixel level accuracy and regional coordinates. ResNet and U-Net are the primary architectures for solving this problem.
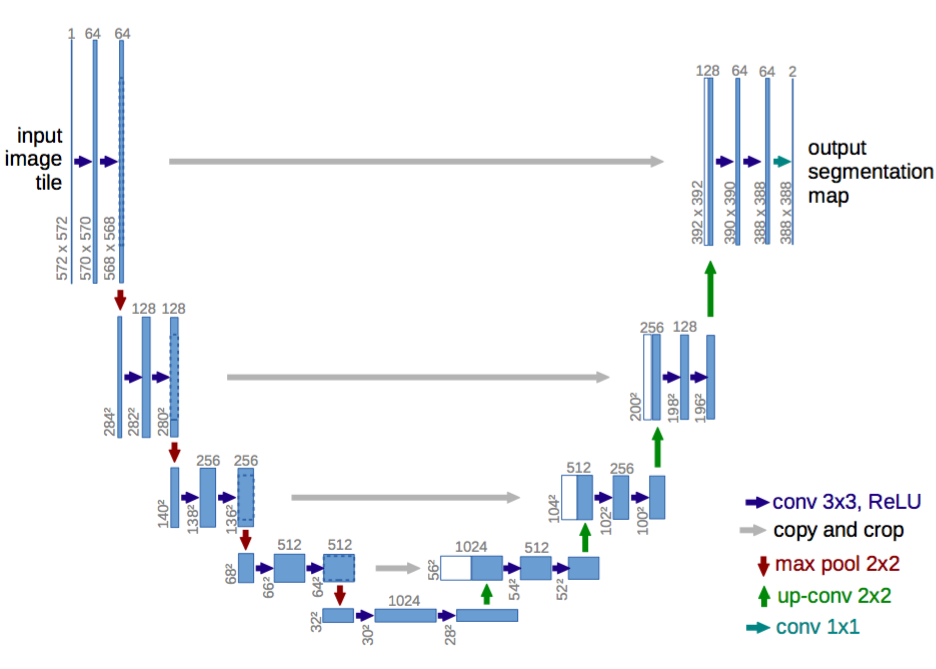
The main feature in the U-Net architecture is "skip connections", which will give the output of a CNN block to another CNN block. This feature will enable the resolution of the processed image and helps enhance the up-sampling of images and retaining the original image resolution.
Computer Vision is a major area of focus for all the deep learning and artificial intelligence related activities. Numerous applications and algorithms are being developed and utilized on a regular basis in commercial, research as well industrial fields.
 About Author
About Author
Aravind Kota works as a Data Scientist in V-Soft Labs. He has profound knowledge in developing applications using Neural Networks concepts in the fields of computer vision, natural language processing, and statistics. He has hands-on experience with tools like MATLAB, Python, and LabVIEW. Also, he is very enthusiastic in developing AI and IoT applications and mentoring many others in this field.
