





MuleSoft's Mule 4 release has lot of improvements compared to Mule 3. Besides adding new features, MuleSoft has made many improvements to the existing Mule 3 features from ease of use in API development to testing. Here is a list of the Mule 3 features that are updated in Mule 4.
Core Concept Simplified
In Mule 3, underlying java types manage the input streams, convert data into java objects which can be accessed by Mule Expression Language (MEL), but Mule 4 avoids unnecessary conversions to Java data types and permits to work with data directly, especially when handling streaming data. Mule 4 offers a framework to handle streaming data in Mule
, where unlike in Mule 3, Mule 4 uses repeatable streams to handle streaming data.
Data Transformation in Mule 4
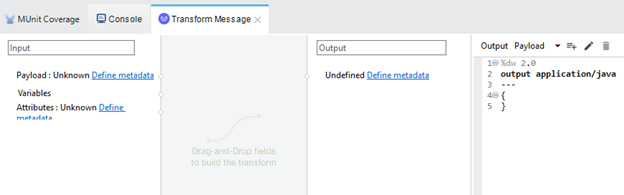
Unlike in Mule 3 which used transformers, Mule 4 introduced DataWeave to transform data. DataWeave is a default expression language, replacing Mule Expression Language (MEL) with a scripting and transformation engine.
Dataweave 1.0 was updated to DataWeave 2.0 where new syntax and features allows users to write expressions and scripts on it. You can call static Java methods by using DataWeave 2.0 expressions.
Batch Process in Mule 4
In Mule 3, there were four phases in batch, whereas the Batch process in Mule 4 has only 3 phases and the input phase doesn’t exist. Mule 4 doesn't require an input phase. The 3 phases include:
- Load and dispatch
- Process
- On complete
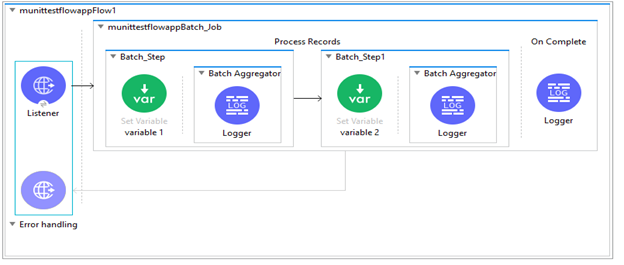
In Mule 4, batch commit has been replaced with a Batch Aggregator component. The Batch Aggregator functionality resembles Batch Commit. But a grouped collection in the Batch Aggregator is defined as a mutable collection. This allows users to modify individual records in groups or variables associated with those. Here one can aggregate records to process in two ways:
- Aggregate a fixed amount of records
- Stream all records
The difference about mutability in both options is, streaming provides one-read forward-only iteration of records whereas the aggregation permits gives you random and/or sequential access to records.
Error Handling in Mule 4
Error handling in Mule 4 provides a simplified way to manage an error and it provides error concepts built directly into Mule. There is no need to write java exceptions directly. Exception strategies are replaced by error handlers which allows you to catch errors based on both type and arbitrary expressions. In Mule 3 there were 6 types of different exception handling strategies. Mule 4 has simplified down to just 3 types of error handling:
- On-Error Continue
- On-Error Propagate
- Try-Catch Scope
Connectors Made Simple
Connectors are simplified as operation-based. In Mule 4, operations are defined directly on the Mule palette in Any Point Studio. As a result, one can drag and drop the operations quickly and development process is made easy with less time. Here are the screenshots for all connectors and respective operations:

One can update the runtime to get all updates of connectors/components enabling lot of flexibility.
Updates Automatically
In Mule 3, Mule’s internal Java libraries was difficult to use because the libraries changed from release to release. But, In Mule 4 the library has been updated with new features which includes a classloader isolation between your application, the runtime, and connector. As a result, any library changes that happen internally will not affect your application.
Non-Blocking and Self-Tuning Runtime Operations
Mule 4 introduced a new execution engine based on non-blocking runtime. It is defined as a task-oriented execution model and it allows you to take advantage of non-blocking IO calls. It avoids performance problems due to incorrect processing strategy configurations.
In Mule 4, each Mule event processor now informs the runtime when it is a CPU intensive, CPU light, or IO intensive operation. Basically, it helps the runtime self-tune for different workloads dynamically and removes the need for users to manage thread pools manually. Mule 4 removes complex tuning requirements to achieve optimum performance.
REST Connect
There is another new feature called REST Connect which can take any API specification such as RAML, Swagger, etc. and it generates a Connector based on the specification. Once you publish an API in Anypoint Exchange 2, then it will automatically convert the API to a connector.
Mule SDK
New to MuleSoft is Mule SDK. Mule SDK is a tool to extend and enhance the functionalities of Mule Runtime. It helps create custom Modules and Connectors. These Modules and Connectors can be used in Mule Applications.
Enricher Upgraded to Target Variable
In Mule 4, Message Enricher was replaced by Target Parameter. The Enricher provided a way to execute a group of message processors and it redirected their output to a variable without side effects to the current message. Now we can use two parameters:
Target (target): The name of the variable needs to provide where you want to store the message data. Names can be numbers, characters, and underscores but hyphens are not allowed in the name.
Target Value (targetValue): The value of the data needs to be store in the target variable. By default, the value is the message that will be in the payload. The field can accept any value that a variable accepts: any supported data type, DataWeave expressions, the keywords payload, attributes, and messages.
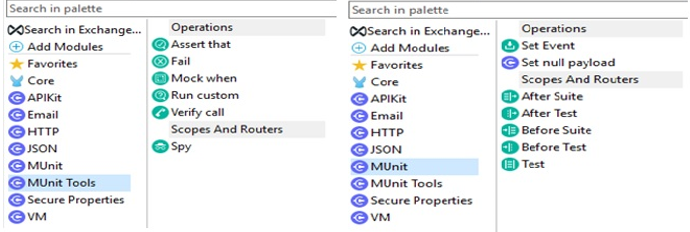
Munit Test
MUnit is a Mule application testing framework and it allows users to easily build automated tests for integrations and APIs. It provides a full suite of integration with unit test capabilities. It is fully integrated with Maven. Here Mule 4 provides two things for Munit one is Munit and other one is Munit tools where all operations and scopes are available. By utilizing Operations and Scopes we can test our applications.
Conclusion
Compared to Mule 3, Mule 4 improvements provided API-led connectivity and facilitates seamless application development and testing.
To learn more about the differences between Mule 3 and Mule 4, click here.






