

Data is vital to making better business decisions. In the age of information revolution, large chunks of data from different formats are being sourced to enterprise databases. With rise of IoT and its adoption in to business environments, huge torrents of data are being routed to businesses. Getting intelligence out of this huge torrent of data is important to promote smart business decisions.
Now-a-days every application needs big data to make real-time based business decisions. This requires fast access and flexible use of data to get intelligence. But businesses are failing to make best use of data, due to usage of nascent methods or tools that strategically organize, store and retrieve data. This problem can be crucial especially for E-Commerce businesses. Solving this problem is the prime objective that resulted in the evolution of MongoDB with NoSQL capabilities.
What is MongoDB?
“MongoDB is an open source, document-oriented database designed with both scalability and developer agility in mind. In MongoDB you store JSON-like documents with dynamic schema. The goal of MongoDB is to bridge the gap between key-value stores (which are fast and scalable) and relational databases (which have rich functionality). “
MongoDB is a NoSQL. Now, companies can store a massive amount of structured data, unstructured data and semi-structured data in real time. NoSQL brings a variety of models, graph formats, documents, search engines, in-memory key values and is particularly useful for storing unstructured data which is growing far more rapidly. This is an alternative for RDBMS where the data schema is designed before the database is built. NoSQL bounds a wide variety of different database technologies that are developed to meet the demand of modern technologies. (Explore the reasons why your enterprise should go with NoSQL.)
Why Businesses Should Choose MongoDB?
MongoDB stores the data in the document format of a JSON object. Each document is stored in the database with related data objects and encapsulated together. As each document is an individual unit and reduces the number of queries required. As the data is stored at one place, extracting data can be achieved with a single database operation without having to refer to different tables located at different locations. This MongoDB increases the performance, speed and ease of maintainability- thereby avoiding the cost and time-delays overheads in data extraction.
Storing data in this format has several advantages:
- The unstructured database can be stored easily as the structure is not known in advance. As with key-value pair i.e., fields, varies from document to document and no schema is required.
- Creating query logic to access the database will be much easier, as there are embedded documents.
- The dynamic schema reduces the cost for migration and makes it agile.
- MongoDB gets better governance over the schema by permitting database administrators to define some authentication within the database. This declaration is derived from the proposed IETF JSON Schema standard.
Why is MongoDB Different From The Rest?
Document Format Data Offers More Flexibility
MongoDB is a no schema database, which means no schema or structure is declared before inserting the data into it. Every record is inserted in the form of collection, and documents. It is not mandatory to have the same set of fields and structure for every document. We can add more fields whenever we want. The main aspect of the MongoDB database is load balancing, which is responsible for the effective results while performing the query operations.
Document Structure
Document structure stored in the MongoDB database and shows the key-value pair format, is shown below:
{
First name: ABC,
Last name: XYZ,
Marks:
[ {
science:70,
maths:90
}]
}
In a relational database, all data is stored in different tables referred by a unique key. Whereas MongoDB stores all data at a single place, because of this reading, the data decreases the query time which decreases the cost to read and write data to the database.
Horizontal Scaling In MongoDB
As MongoDB consists of a large number of multi-format data collections, it demands a lot of CPU utilization. In order to overcome this, sharding is done over the data. Sharding is the process of splitting a large number of data sets in to small parts. Horizontal scaling is performed on the data sets, as vertical scaling is too expensive. 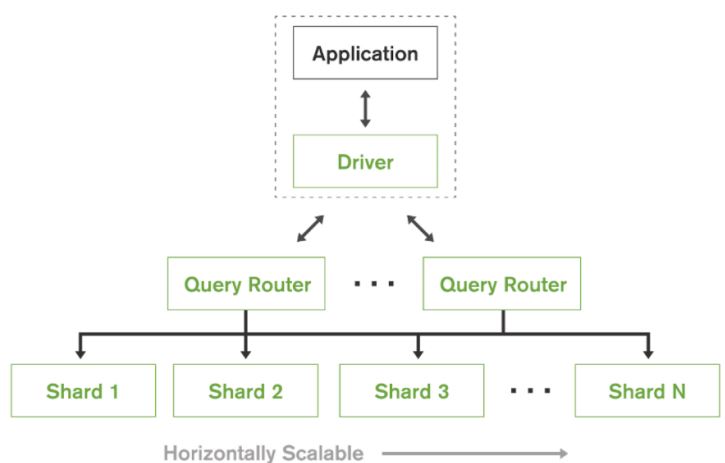
Figure: Automatic sharding for horizontal scale-out
Indexing In MongoDB
Indexing is used to find the data more quickly and easily. Indexing in the MongoDB plays an important role in the effective execution of the queries. When data is indexed, the queries will be condensed and the number of records are skimmed through. The default indexing for MongoDB is “_id”. We can do indexing on any field that encompasses in the document.
Query to create indexing:
db.collection.createIndex({“fieldname”: “value”});
MongoDB Executes Complex Dynamic Queries
MongoDB supports complex queries in reading the data from the collections. It supports operations like:
- Sorting on one or more fields.
- Retrieving only the selected fields from the document.
- It will be easy to implement pagination by using cursor like skip (), and limit ().
MongoDB In AWS
AWS enables to set up an infrastructure that supports MongoDB deployment in a form with great flexibility, scalability and cost-effective manner for AWS Cloud. MongoDB atlas can be used to deploy a fully managed database service. It can create a VPC (Virtual Private Cloud) to automate potentially time-consuming tasks such as managing, monitoring, and back up.
Replica sets of data are created containing the same data to be available for the services- if any set of data is fails to load. In the era of globally distributed businesses, these replica sets securely aid data distribution across the world with ease. In production, it uses to contain 3 cluster sets:
- Primary
- Secondary0
- Secondary1
In general, read operations can be performed from the secondary clusters, but write operations need to be done on the primary cluster, eventually, it will be updated into the replica sets.
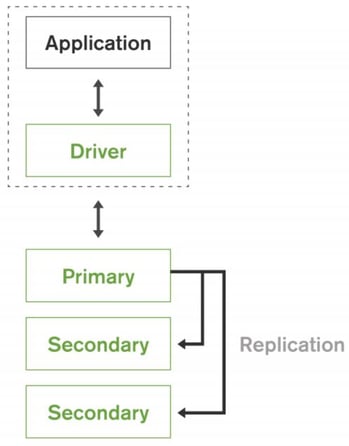
Figure: Self-healing MongoDB replica sets for continuous availability
How MongoDB Aids Cloud Computing
Cloud computing is providing software product services over the internet managed as Infrastructure-as-a-service, which is more inexpensive, elastic, and reliable. Cloud computing provides scalability, agility, lower cost and a faster response time. As NoSQL databases are able to handle the load by splitting the data among the servers it makes fit for the cloud computing usage.
One of the MongoDB competencies is sharing the databases -it can automatically distribute the data among the servers through replica sets. This way scaling is achieved in the form of horizontal scaling, so that the data can be read and inserted fast. MongoDB automatically manages the set of redundant servers, called replica sets to maintain availability and data integrity across cloud operations too.

About The Author
![]()
![]()
 Kalyan Manthena is the Web Developer at V-Soft Consulting. He holds 6+ years of experience in web Application Development, web programming, Server technologies, Database Design, and Plug-in development. Apart from these, he also possesses great amount of skills in online tools like WordPress and frameworks like Bootstrap and Angular Materialize. Apart from these, he also holds good knowledge in MySQL, Manual Testing and ServiceNow.
Kalyan Manthena is the Web Developer at V-Soft Consulting. He holds 6+ years of experience in web Application Development, web programming, Server technologies, Database Design, and Plug-in development. Apart from these, he also possesses great amount of skills in online tools like WordPress and frameworks like Bootstrap and Angular Materialize. Apart from these, he also holds good knowledge in MySQL, Manual Testing and ServiceNow.
